
The Beaver Works Summer Institute program was created in late 2015 by several Lincoln Laboratory staff members, in conjunction with MIT students and faculty. The task for the program's first implementation (in the summer of 2016) was the programming of autonomous remote-control rally cars running ROS (Robot Operating System). This task was based on the objectives of two MIT courses, both taught by Professor Sertac Karaman: "Robotics Science and Systems" (6.141), as well as a short IAP course dedicated to programming the cars. The ultimate goal of the summer program was to get students to explore ROS, and to take advantage of the cars' onboard sensors and supercomputers to develop their own machine vision and autonomous driving algorithms. The program lasted four weeks, each of which included a different topic of interest, from moving a car autonomously along a wall, to detecting colored markers and allowing the car to perform localization. Each day included several lectures from both program staff and outside lecturers, all of which were partially or directly related to the program content. In between lectures, the students would complete labs in which they would develop algorithms allowing the cars to execute given sets of instructions autonomously. The theme of the first week was getting a car to move by manually sending it commands, before implementing an autonomous motor controller (such as PID). The second week's topic was the detection of colored markers with the car's onboard stereo camera. The third week included the combination of marker detection and drive code, as well as the development of an obstacle avoidance algorithm. And lastly, the fourth week involved the combination of all the algorithms developed in preparation for the final grand prix race.

Figure 1. RACECAR Hardware (1). The above diagram highlights several key components of each RACECAR (Rapid Autonomous Complex-Environment Competing Ackermann-steering Robot) system.
The chasses of the cars we used during the BWSI program were originally from Traxxas model 74076 cars, which are 1/10 scale remote control rally cars with four-wheel drive and front-wheel Ackermann steering. The brushless motors and some other electrical components mounted on the chassis were moved around to make space for holding an extra battery, USB hub, wiring, and sensors that were added on.
Each car had a series of onboard sensors for various purposes. First, each car was equipped with a Hokuyo UST-10LX LIDAR for detecting a two-dimensional laser scan of obstacles within a 270-degree range in front of the car. Each Hokuyo LIDAR scanner would continuously return an array of 1080 ranges indicating how far a laser signal could travel in a given direction from the car, one for each quarter of a degree. The laser would turn counterclockwise at a constant rate of about 40 Hz, and would report its arrays of ranges over an Ethernet connection at about the same rate. It could very accurately detect ranges from as close as about 0.06 m to as far as about 10 m.


Figure 2. The Hokuyo UST-10LX Scanning Laser Rangefinder. This figure contains an image of the Hokuyo LIDAR we used on our cars, as well as its counterclockwise path.
Each car also had a Sensorlabs Zed stereo camera mounted in front. As a passive stereo camera, the Zed consisted of two color cameras side by side, and could use the data from these cameras for depth perception from about 0.7 m to 20 m. Although we never utilized the depth perception functionality of these cameras, we often used one camera stream or the other to detect colored markers ahead of the car.

Figure 3. The Zed Stereo Camera. This is an image of the Stereolabs Zed passive stereo camera we used for marker detection on our cars.
Next, each car had a Sparkfun model 10736 Inertial Measurement Unit (IMU) with 9 degrees of freedom. Each IMU contained three sensors - a three-axis accelerometer for measuring translational acceleration, a three-axis gyroscope for measuring angular velocity, and a three-axis magnetometer for measuring translational field strength - creating 9 degrees of freedom all together. Although we always had the option of using data from the IMU, it was often unreliable due to either poor calibration or magnetic interference.

Figure 4. The Sparkfun IMU. Above is an image of the Sparkfun model 10736 IMU that was mounted on each of our cars.
Finally, each car had a mounted NVIDIA Jetson TX1 supercomputer with a 256-core NVIDIA Maxwell GPU and 4 GB of memory for running ROS on the Linux operating system and performing all of the calculations on incoming sensor data.

Figure 5. The NVIDIA Jetson TX1 Supercomputer. The image above is of the NVIDIA Jetson Tegra X1 supercomputer we used for running all of our code on our racecar.
Additionally, to control the driving and steering on the car, each car had a VESC motor controller connected to the onboard TX1 computer, which would send out driving commands to the motor controller via ROS. (2)
There were multiple ways to connect to a car's onboard computer. The primary way was to use the SSH protocol to connect the car's computer from a machine natively or virtually running Linux on the same network (either wirelessly or through Ethernet), and execute commands remotely. An alternative method involved connecting the car's Jetson to an external monitor via HDMI, and connecting a keyboard and mouse to the car's USB hub (connected to the car's computer) for typing and running commands. A major downside to the latter method, however, was that the HDMI cable made it virtually impossible to run any driving commands on the car, making it necessary to keep the car stationary while connected to a monitor.
A key component of our racecars was the operating system through which we connected their sensor data to their driving controllers in order to make them drive autonomously: the Robot Operating System (ROS). For programming our cars, we used the 'Indigo' version of ROS. We used ROS primarily because it is a powerful, flexible, yet complex open-source system used widely in both robotics research and industry. A major benefit to using ROS is that it is language independent, has support for multiple languages (such as C++ and Python), and consists primarily of contributed algorithms, drivers, and applications which may be reused for different robotics applications. In a typical ROS application, there are usually hundreds of nodes running at the same time, which make up a network known as the "ROS Computational Graph." Within this network, programs known as "nodes" communicate with each other by sending data as "messages" over channels known as "topics." A sensor on a robot, for example, may publish messages with output data to a topic, which a node (usually a script written in any programming language supported by ROS) may "subscribe" to and then use to determine what the robot must do next. Each node may subscribe or publish to one or more topics. (3)
Each topic holds only one certain type of message. A type of message can be anything from a simple, standard message type such as a string or a float, to a more complex custom message that may carry multiple variables of multiple data types. For some applications such as marker detection, custom message types were very useful for reporting all of the information for a detected marker in a single message. For launching multiple nodes at the same time, we used a type of file known as a 'launch' file, an XML-style file containing the names of all of the nodes we wanted to launch. Another feature we often used for testing was the rosbag functionality in ROS, which allowed us to create recordings of all ROS activity (messages sent over all or specified topics) over a given time interval and then play it back as if it were happening in real time. There were several ways in which we could check what was happening between different ROS nodes and what messages were being sent over certain topics. For a general overview, we could check what the whole ROS computation graph itself looked like through the rqt_graph module.

Figure 6. The rqt_graph Module. Above is an image of what the ROS computational graph looked like when running a simulation of the racecar (which tended to create the same topics and messages as the actual racecar).
Another very useful ROS function was rostopic echo, which allowed us to see all of the messages being published to a given topic.

Figure 7. The rostopic echo Function. When we used the rostopic echo function on our contour detection channel, we could see when a contour was being detected, as well as the detected contour's color, size, and location.
The programming language we used to write all of our nodes was Python 2.7, which, like all other programming languages supported by ROS, would work perfectly well even with nodes written in other languages. We used Python primarily because it is an intuitive, easy-to-learn language with a flexible syntax, and is nevertheless very powerful due to its many available libraries. To use Python with ROS, we had to import the rospy library, which allowed our applications to integrate with the ROS environment. Many ROS nodes run exclusively on callback functions, which means that most ROS programs are triggered by certain events, such as timers (4). When a program is finished executing, it enters ROS's main event loop, known as 'spin.' In this way, most ROS nodes operate in loops until they either are unregistered in the code or no longer receive suitable data. A ROS master node, necessary for any other nodes to run, is responsible for logging data and maintaining connections between publishing and subscribing nodes.
The operating system we used throughout the program was Ubuntu Linux 14.04. Many chose to run this operating system virtually on their personal computers, but all of the cars had an ARM version of Ubuntu running natively on their TX1 computers. We used Ubuntu Linux mainly because it is easily customizable, has a powerful command line interface, and has support for embedded systems and supercomputers (5). Most chose to use either Terminator or TMux for executing shell commands, and some used text editors such as Vim or Emacs for editing code, while others used larger IDE's such as Pycharm. Shell commands used often were the 'ssh' command, for connecting to and running commands remotely on the cars; the 'source' command, for setting up all of the necessary environment variables for a given ROS package; the 'rosrun' command, for running ROS nodes separately; the 'roslaunch' command, for running multiple nodes at a time; and the 'rostopic' command, for listing and inspecting the data being published to a given topic.
Two major Python libraries we used for programming vision and driving code for our cars were OpenCV and Numpy. OpenCV is a large, open-source computer vision library with many functionalities and a wide range of applications. The OpenCV functionality we used most was the color filtering function, which we used to detect markers of different colors. Numpy is a popular library for manipulating large sets of numerical data easily. This library was very useful for our potential field driving algorithm (to be explained later), which required some multivariable calculus-based data analysis. All of the code my group wrote went into private code repositories stored on Github, a large online code repository storage with powerful version tracking functionality. This way, all of our code stayed safe, organized, and updated.
During the first week, students explored a method of manually publishing drive messages to the car's drive command topic, and eventually created their own Python (rospy) nodes to publish these messages automatically. When a car's teleoperation file is launch with the roslaunch command, the car's drive system is automatically started and configured. Within a car's driving system are numerous nodes, each of which serves an important purpose. One of the most important nodes is called 'ackermann_cmd_mux,' and acts like a multiplexer with respect to the different driving command input methods. There are three main input methods: navigation, teleop, and safety. Although the joystick input uses the teleop method regularly, any of these three methods may be used to publish drive commands manually, and the ackermann_cmd_mux node will select the input method that publishes at the highest rate to send to the motor controller.
In order to send drive commands manually to the car, we published drive messages to the navigation input method at a minimum rate of 10-15 Hz. In order to make the publication of drive messages automatically dependent on data from the car's Hokuyo LIDAR, however, we needed to make a node that was a subscriber as well as publisher - one which subscribed to the LIDAR's output scan topic, processed the data every time it received a message from the laser, and published the corresponding drive angle along with a set speed to the navigation topic. The 'wall' along which the car needed to drive looked similar to the one in the following testing setup (Figure 8).

Figure 8. Wall Following Setup. The above photo shows a testing setup for wall following very similar to the one used during the actual challenge and during the final grand prix race. The car needed to rely primarily on LIDAR data to determine the correct driving angle.
My group tried three different algorithms for determining the car's new steering angle every time the node received laser data and calculated the amount of error. Error in our case was calculated with the following equation: $$E=D_{Desired}-D_{Actual}$$ Although $D_{Desired}$ is a constant, $D_{Actual}$, the car's distance from the wall at a given time, can be calculated through numerous different methods, each of which have their pros and cons. My group used the following two equations to determine this variable: $$D_{Actual}=min\left(array\_of\_pts\left[Index_1:Index_2\right]\right)$$ $$D_{Actual}=\frac{R_1R_2}{2\sqrt{\left.(R_1\right){}^2+\left.(R_2\right){}^2-\sqrt{3}R_1R_2}}$$
In the equations above, $Index_1$ and $Index_2$ specify the bounds of a set of ranges in the $array\_of\_pts$ array the laser returned. $R_1$ and $R_2$ are two specific ranges in the array at a certain given angle apart (usually thirty degrees). Different predetermined indices and ranges were used above depending on the side from which the car followed the wall, and although only one of the above algorithms was required, my group took the average of the outputs of the two methods.
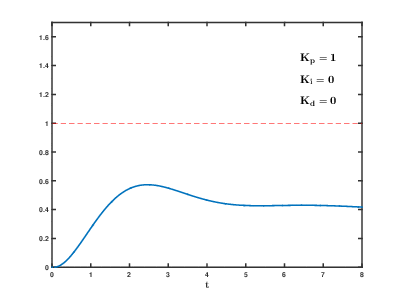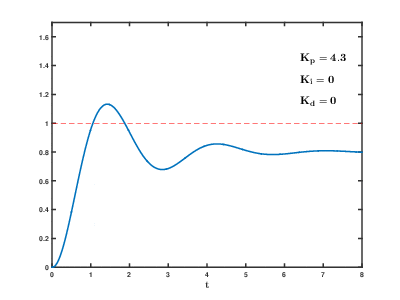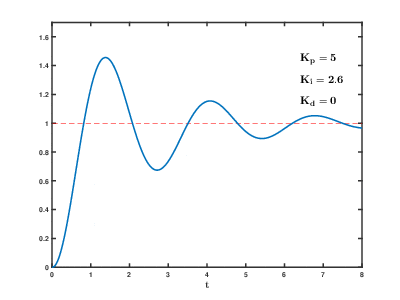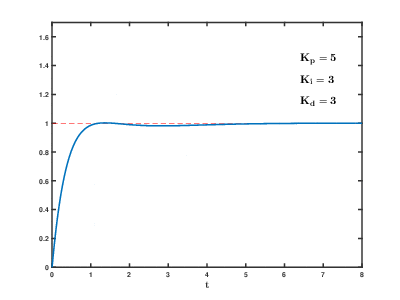
The first of three drive control algorithms (mentioned above) that my group tried was a simple 'bang-bang' controller, which changes the steering angle between a constant -1 radian and 1 radian based on whether the error is negative or positive. This drive control method was the most unstable and least efficient of the three we tried, as there was no correlation between the error and the change of error over time. A slightly improved method my group implemented next was the same bang-bang controller, but with a threshold on the error value needed in order to change the steering angle to 1 or -1 radian. If the error was not above the threshold, the car would go straight. Below is a video of the car driving with a threshold of 0.07 meters:
The third drive controller we implemented was a PID (Proportion + Integral + Derivative) algorithm. This was a lot more responsive and reliable than the bang-bang controllers, as it took into account the error itself, the derivative or its change over time, and the integral of its change over time. We found a new error value, which we also used as the car's new steering angle, with the following PID formula:$$E_{New} = K_pE + K_i\int _0^tEdt + K_d{d \over dt}E = SteeringAngle$$In the equation above, $E$ is the original error obtained using the two previous euqations, and $K_p$, $K_i$, and $K_d$ are the proportional, integral, and derivative constants respectively. Below are several videos of our car driving with the use of a PID controller:
These videos reveal a common challenge in using a PID controller: coming up with the right constants to use. Although the controller itself worked very efficiently and reliably, the video on the left demonstrates how poorly car turned, and the video on the right demonstrates how often the car oscillated when we used unideal constants. The following animation shows how tweaking PID values changes the error over time (6):

Overall, we determined that for simply following a wall, a PID controller may be the most effective drive controller, granted that the constants used are correct.
During the second week, the program staff introduced the students to OpenCV, a large, open-source computer vision library, which the students would eventually use to filter out colored markers in a video stream. The final challenge for the week was for a racecar to autonomously drive in the direction of either a red or green colored marker, determine marker's color, make either a left or right turn based on the color of the marker, and follow the wall behind the marker for a certain distance. A diagram of the challenge layout is below (7):

Figure 9. Week 2 Challenge: Making the Correct Turn. The image above portrays the setup of the second week's final challenge.
For this challenge, students would use both the LIDAR sensor and the Zed stereo camera on the car. In order to process both camera footage and laser scan data, the series of nodes that my group created for this challenge needed to subscribe to both the scan topic and the camera's 'image_rect_color' topic, which streamed frames from one of the two cameras in the Zed.
The marker detection algorithm most groups used was similar to the following:
Once OpenCV detected contours in an image, information could be published about the largest contour. To stream information about contours (or 'blobs') the camera saw, my group used a separate topic with a custom message type containing information about a blob's size, color, and location in the image. We created one node to detect the contours and publish information about them, and another node to subscribe to the published information and steer the car correspondingly towards the center of a given contour with the use of a PID controller.
A unique feature of my group's contour-tracking node was the addition of OpenCV 'trackbar' functionality to assist with determining the correct lower and upper HSV value bounds to use for each color's mask. The use of a window with these sliders along with the filtered image itself in real time helped my group significantly. Figure 10 below shows what our set of trackbars looked like, and how the trackbars influenced our workflow.



Figure 10. Trackbar Workflow and Target Information. The image on the left shows an unfiltered frame which comes in from a car's Zed camera. The middle image shows the unique and very convenient approach my group took to picking out the upper and lower HSV values for filtering out unneeded color. Our interface contained six trackbars: three for lower and three for upper bounds, and each representing either and H, S, or V value. The filtered image displayed would only contain pixels within the set bounds. The image on the right shows the contents of the custom message type we used to describe a detected contour. Variables included the RGB color values of the contour's center, as well as the size of the contour and the coordinates of its center on the screen.
Although our contour-tracking node only served the purpose of publishing contour information and displaying the tuning window when the tuning functionality was manually chosen at startup, our driving node had several functions, which occurred in sequence. Because each subscriber must have a callback method, only one variable was used to subscribe to either camera (contour information) data or laser scan data at any given time. Before a contour of a given size was detected (signaling that the car had almost reached the wall), this variable would represent a subscription to contour information, which would allow a PID controller to steer the car towards the center of a detected contour. The color of this contour, also included in the stream of information, would be used to determine whether the car was to eventually follow the wall ahead from the right or left side. Once the contour reached a certain size, which was checked at every iteration of the contour data callback, the contour information subscriber would be unregistered, and the same variable would then used to instantiate a laser scan data subscriber. The callback for this laser scan data would first push the car at a constant speed and steering angle to either the right or the left for about a second (managed by a timer and counter variable), and would then use the same PID controller with different PID values to keep the car moving along the wall, similarly to the previous week's challenge.
Despite having the trackbars to assist with the determination of proper HSV values to search for given colors, there were nevertheless certain limitations of using OpenCV that made it especially difficult to create a solid vision system. The most prevalent of these challenges was the inability to dynamically adjust to different lighting conditions. As the lighting was slightly different in each room and during different times of day, the constant values we would determine in one test would have to be changed for another, and with our simplistic approach of setting constant values in the code with each test, there was virtually no way around this challenge. The trackbars, as expected, helped ease the readjustment of values before each test. Several videos of our car completing the challenege, taken both from the car and from a birds-eye view, are below.
Turning Right on Green
Turning Left on Red
Additionally, because the magnitude of change in error over time in the case of steering towards a contour was very different than that in the case of staying at a certain distance from the wall, significantly different PID values were used for one task as opposed to the other, and therefore a graph of contour-tracking error over time looks different from a graph of wall-following error over time (Figure 11).

Figure 11. Contour-Tracking vs. Wall-Tracking Error over Time. The image above shows a graph of error over time for contour tracking (on the left) vs wall-following (on the right). The PID values used for contour-tracking were P=0.005, I=0, D=0, and the values for wall-following were P=1.0, I=0, D=0.8. This data was collected through a Gazebo simulation that very closely replicated the setup of the challenge.
Based on the results of using PID in the cases of contour-tracking and wall-following, higher PID values lead to more responsiveness, but also to more frequent overshooting and oscillation. For this challenge, we decided to use higher values for wall-following because the car's steering needed to be much more responsive when keeping the car at a certain distance from a wall than when keeping the car aimed directly at a target when driving forward.
Our challenge during the third week was to program our car to explore an open area with different obstacles without colliding with the obstacles or boundaries. Attached to each obstacle was a shape of a random color, or a photo pasted onto a pink background. The car had to identify the shapes and photos it saw, along with their colors, and save labeled photos of those shapes into a given directory. A photo of the challenge setup is below.

Figure 12. Week 3 Challenge Setup. This photo shows the bounded area in which the third week's challenge took place. Each car was to identify the shapes, photos, and colors it saw, and to save photos of what it saw to a given directory.
A simple wall following algorithm such as the one used during the first two weeks would not necessarily work for this challenge, as the simple wall following algorithm we had been using used only a limited range of LIDAR data, and therefore only tracked a small portion of one of the walls. The algorithm needed for the task of avoiding all obstacles would need to take all of the obstacles in the LIDAR data into account, and it was for this reason that a 'potential field' algorithm was used.
With the potential field algorithm, all obstacles around a car would form a potential field such that the car would be attracted to free space and repelled from surrounded obstacles (8). From a physics point of view, both the car and the obstacles around it may be considered positively-charged particles, while any free space around the car may be considered negatively-charged particles.


Figure 13. Potential Field Analysis and Results (9). The above images show the distribution of the potential field for a given set of obstacles (on the left), as well as the estimated trajectories for a robot moving among those obstacles (on the right).
In my group's implementation of the potential field algorithm, the gradient of each range returned from the LIDAR would be calculated. The potential $(U)$ of each obstacle (or the force that each obstacle would have on the car) was inversely proportional to the distance between the car and the obstacle: $$U_{obstacle}=\frac{1}{||\text{pos}_{car}-pos_{obstacle}||}=\frac{1}{\sqrt{\left(x_{car}-x_{obstacle}\right){}^2+\left(y_{car}-y_{obstacle}\right){}^2}}$$To figure out the direction pointing down the potential surface, and the total influence of nearby obstacles on the steering angle and speed of the car, we found the gradient at each surrounding LIDAR data point with respect to the car's coordinates, $x_{car}$ and $y_{car}$:$$\frac{\partial U_{obstacle}}{\partial x_{car}}=\frac{\partial }{\partial x_{car}}\frac{1}{\sqrt{\left(x_{car}-x_{obstacle}\right){}^2+\left(y_{car}-y_{obstacle}\right){}^2}}=-\frac{\left(x_{car}-x_{obstacle}\right)}{\left(\left(x_{car}-x_{obstacle}\right){}^2+\left(y_{car}-y_{obstacle}\right){}^2\right){}^{\frac{3}{2}}}$$
AND
$$\frac{\partial U_{obstacle}}{\partial y_{car}}=\frac{\partial }{\partial y_{car}}\frac{1}{\sqrt{\left(x_{car}-x_{obstacle}\right){}^2+\left(y_{car}-y_{obstacle}\right){}^2}}=-\frac{\left(y_{car}-y_{obstacle}\right)}{\left(\left(x_{car}-x_{obstacle}\right){}^2+\left(y_{car}-y_{obstacle}\right){}^2\right){}^{\frac{3}{2}}}$$
Next, to determine the total potential $(U_{total})$, we found the sum of all gradients with respect to $x_{car}$ and $y_{car}$ separately:$$\frac{\partial U_{total}}{\partial x_{car}}=\underset{i=0}{\overset{n-1}{\sum }}\frac{\partial U_i}{\partial x_{car}}$$
AND
$$\frac{\partial U_{total}}{\partial y_{car}}=\underset{i=0}{\overset{n-1}{\sum }}\frac{\partial U_i}{\partial y_{car}}$$
To determine the steering angle, we used only the x-component of the total gradient:$$SteeringAngle=k_{steer}*\frac{\partial U_{total}}{\partial x_{car}}$$In the equation above, $k_{steer}$ is a constant used to set the amount of influence the potential field had on the car's steering angle. In a similar way, we used the magnitude of the total potential to determine the speed of the car, which could be negative based on the magnitude of the potential's y-component, causing the car to go in reverse when it encountered a set of obstacles it could not overcome:$$Speed=k_{speed}*||{\left\langle \frac{\partial U_{total}}{\partial x_{car}},\frac{\partial U_{total}}{\partial y_{car}}\right\rangle}|| sign\left(\frac{\partial U_{total}}{\partial y_{car}}\right)$$In the equation above, kspeed determined the amount of influence that the potential field had on the car's speed. Because the equation above often caused the car to get stuck attempting to move forward and reversing due to speed limitations in several places, we eventually changed the way speed was calculated. Instead of applying speed directly in proportion to the magnitude of the total potential, we used an equation that simulated the gradual decay of the car's velocity due to friction, and lightly influenced the car's actual speed with the potential-based speed value:$$Speed_{current}=\mu *Speed_{current}+\alpha *Speed_{potential}$$In the above equation, $\mu$ represents a constant close to but less than 1 which simulates the decay of speed over time (we used 0.95 for this value), and $\alpha$ represents a constant close to but greater than 0 which determines how much the potential-based speed value will influence the buildup of speed overall (we used 0.06 for this value). With this approach, the car handled obstacles much smoother, and therefore functioned in a more predictable manner. To help the car retreat from obstacles, the steering was inverted with a negative constant whenever the overall speed dropped below 0. The adjustment of the constants mentioned here really helped fine-tune the algorithm.
The animation below portrays the results of using the potential field algorithm (10):

The video on the left is of the LIDAR data received on the car, while the video on the right is a 3D rendering of the potential field created by the LIDAR data. The green arrow is pointing in the direction of the car's calculated steering angle.
The goal of the fourth week of the program was for all of the teams to clean up and prepare their code from the previous three weeks for the final grand prix race. To organize code, my group created one final code repository on Github to store the launch files and scripts used for each of the challenges. Not only did this put everything in one place for ease of access, but it also made all of the scripts a lot easier to launch. The final event involved not only completing a grand prix race around a track, but it also involved the identification of a colored marker for making the correct turn at a fork, and a separate challenge of identifying colored obstacles and photos while driving around on a separate course.

Figure 14. Map of the Grand Prix Race Course. The above image is an illustration of the course used for the grand prix race event, located in Walker Memorial on MIT's campus.
The course consisted of a loop around the floor of Walker Memorial, and included multiple turns, a possible shortcut to one of the sections, and colored markers along the walls for optional localization. Whether or not the shortcut was closed off was indicated by either a red (closed) or a green (open) colored marker above the shortcut entrance. To decide whether or not the shortcut was open, a car would have to identify the color of the marker when it came to the fork (Figure 15), and turn accordingly.

Figure 15. Shortcut Opening When Closed. The above image shows the fork, with the shortcut ahead. At this time, however, the shortcut was closed off, and therefore had a red marker over the entrance to indicate the closure. If a car failed to turn right at the red marker, it would inevitably collide with the barrier on the other end of the shortcut.
Many of the groups, including mine, reused most of their potential field and/or wall-following code for driving, and their visual servoing code for marker detection. What my group did to combine the functionalities of our previous scripts was write a master node script which acted as a multiplexer for drive commands. This master node would take in all of the drive commands published by contour-detection, wall-following, and potential field nodes and decide which drive messages to publish based on the situation. Although this approach did show promise, there were several needed changes that became apparent after the initial tests we conducted on the course.
First and foremost, due to the very dim and inconsistent lighting on the course during different times of day and different weather conditions, our sensitive vision algorithm was either working, partially working, or not working at all. Contour sizes would often differ from time to time, and this would cause the master node, which depended primarily on contour size, to switch between one drive message source and another either too late or too soon. To overcome false triggers, we tuned the HSV filtering bounds constantly, and began to use the rolling binary average of a detected contour in order to further filter out noise. Additionally, we needed to tweak some of the potential field algorithm values, such as $k_{steer}$ and $k_{speed}$, in order for the car to perform well on the rest of the track.
Despite several disappointing tests in the beginning, we were eventually able to establish a fairly solid combination of contour detection and potential fields to drive the car, along with what seemed to be working constants. With our algorithm, we placed second in time trials at the grand prix event. Below is a video of our three time trials, the first one being our fastest due to the shortcut:
In conclusion, our efforts during the program were a huge success, but with this success came many challenges, failures, and discoveries along the way. In the first week, we saw both the pros and the cons of different types of wall-following algorithms. Although PID came out above the rest, having improper PID values often led to overshooting on turns, frequent oscillations, and other unwanted behavior. The visual servoing challenge we received the second week demonstrated how sensitive and fragile the simple vision systems we developed were. A huge challenge was to have vision working in the room where it would be put to the test, even though each room apparently had very different lighting during different times of day and during different types of weather than other rooms. One of the biggest challenges during the third week was to have both a smart, adaptable driving controller such as the potential field algorithm, as well as an emergency stopping node, running at the same time with minimal interference between the two. Lastly, working as a team on all of these challenges proved to be yet another tough trial, fortunately one in which everyone managed to succeed.
In the future, it would be interesting to see what the cars can do better when more sensors are implemented - sensors such as the active Structure.io depth sensor rather than the unreliable passive depth sensing on the Zed camera. Another interesting future project would be to use libraries other than OpenCV for developing vision algorithms. This could possibly include libraries with more machine learning and data analysis integration, and would eliminate the limitations we encountered when using OpenCV for our application.
As a team member, I myself learned several very useful lessons. First, I learned about the difficulty of integrating multiple people's code when working on a large, challenging real-world problem. There were at least several times during the program when our lack of understanding of each other's code, or the lack of cooperation or communication, brought us down significantly in our challenge. Another major difficulty I encountered was the possibly catastrophic outcome of modifying code at the last minute when there is no 'code freeze' and when I was tempted to take that risk. I experienced such a catastrophic outcome myself when a repository reset caused the loss of all of my local code modifications during one of the tech challenges. The lesson I learned really emphasized the necessity of having a code freeze or deadline for all of my coding projects.
Looking back once again at the major technical lesson I learned both from working on the racecars and listening to the program's many guest lecturers, I can see that the vast field of autonomous cars, along with the rapidly expanding field of general autonomous robotics, still has challenges that will take much time and thought to solve. There are limitations in every sensor's abilities, and robots simply cannot think as humans can - at least not yet. To program a robot to complete a seemingly simple task for a human may take a surprisingly complex algorithm, and as time goes on, the algorithms required will only become more and more complex. This is why I hope to go into artificial intelligence and autonomous robotics - namely, to try to solve what has yet to be solved in order for robots, regardless of the situation or the environment, to think and act more like humans: autonomously.
{kind=link}
{kind=link}